


Mijn Agent of chatbot lijkt mijn tabel niet correct te begrijpen of te interpreteren!
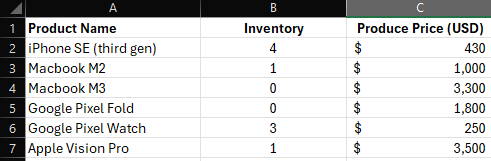
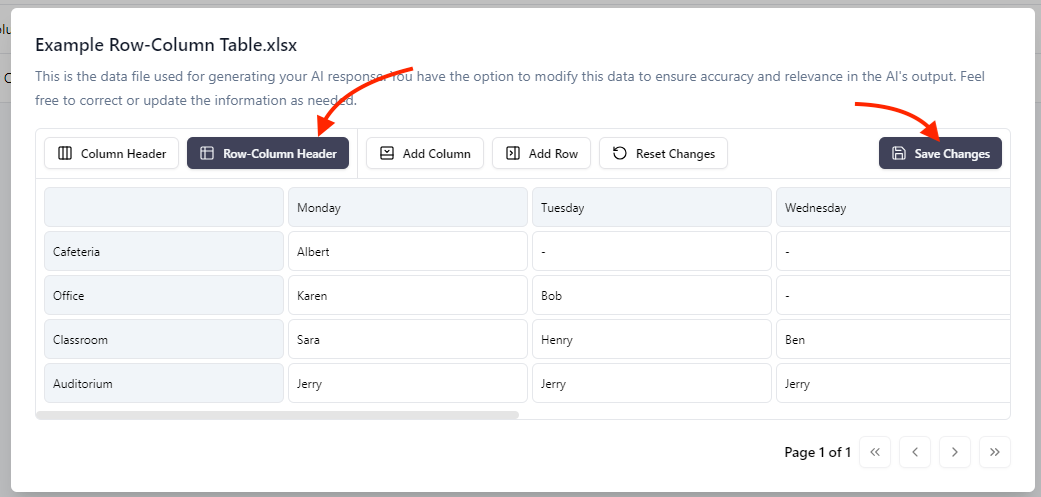
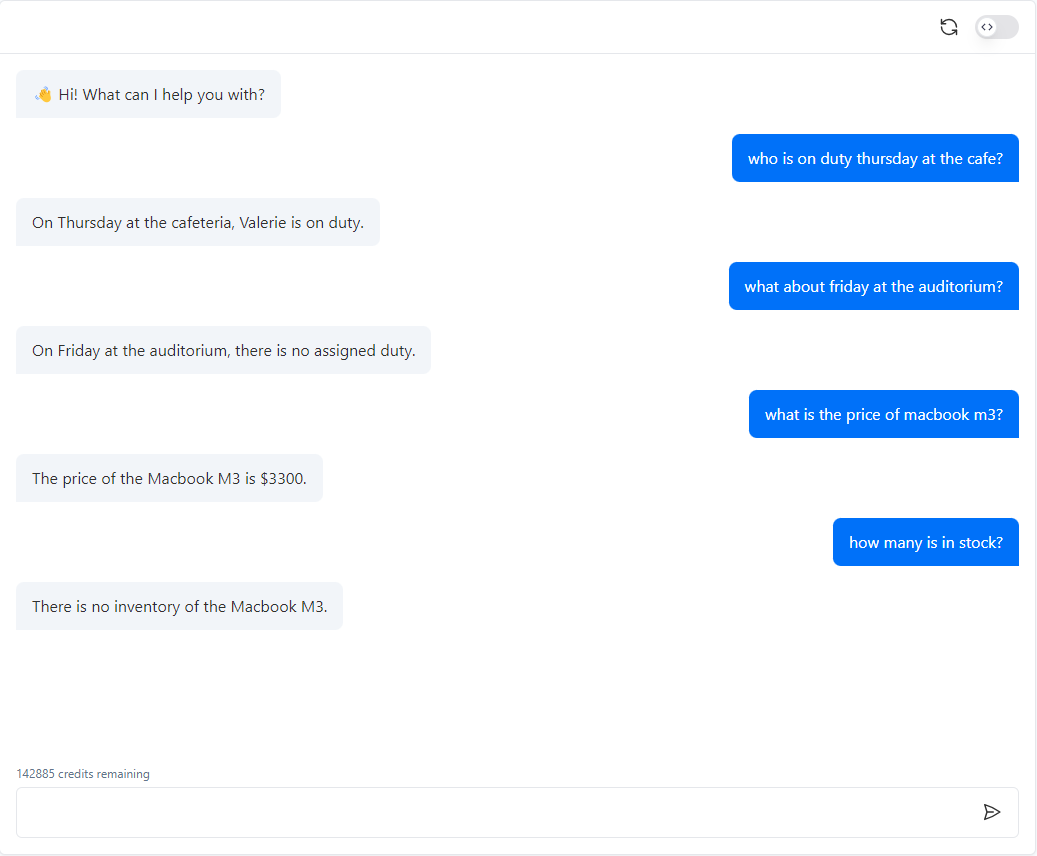
Grote taalmodellen (LLMs) zoals GPT-4 zijn buitengewoon bedreven in het werken met ongestructureerde tekstgegevens. Met een multimodale trainingsmethode kunnen LLMs zelfs visuele of beeldgegevens interpreteren en associëren met natuurlijke taal (zoals GPT-Vision). Echter, getabelleerde gegevens zijn heel anders. Er is geen universele set regels of standaardtaalpatronen als het gaat om het weergeven van gestructureerde informatie. Gezien de probabilistische aard van LLMs zijn ze van nature niet begaafd in het direct verwerken van dit type gegevens. Een artikel van Microsoft Research heeft recent de prestaties van GPT-4 geëvalueerd bij het verwerken van gestructureerde gegevens. Hierin worden de modelprestaties besproken tegen talrijke programmatische representaties van gestructureerde gegevens.
Source: https://www.microsoft.com/en-us/research/blog/improving-llm-understanding-of-structured-data-and-exploring-advanced-prompting-methods/ Chatwize gebruikt momenteel een versie van JSON om tabellen te verwerken. Hoewel het niet perfect is, ondersteunt het een beperkt aantal use-cases wanneer bot-makers chatbots willen trainen met gestructureerde gegevens. We begrijpen dat veel use-cases veel grotere en complexere datasets betreffen die zelfs in real-time kunnen worden bijgewerkt. De statische tabelfunctie binnen Chatwize is hier niet voor geoptimaliseerd, en we raden je in plaats daarvan aan om te kijken naar function-calling. De meest robuuste en “legitieme” manier om retrieval augmented generation (RAG) toe te passen op gestructureerde gegevens is via function calling, waarbij je aangepaste functies ontwerpt en host met gesjabloneerde SQL-query’s om specifieke gegevensfragmenten op te halen en deze naar je Chatwize-chatbot te voeren als aanvullende RAG-context on-demand. Dit vereist echter wel wat programmering en serverhosting aan jouw kant. We werken aan enkele concrete voorbeelden van deze setup, dus we waarderen je geduld terwijl we onze documentatie verbeteren.