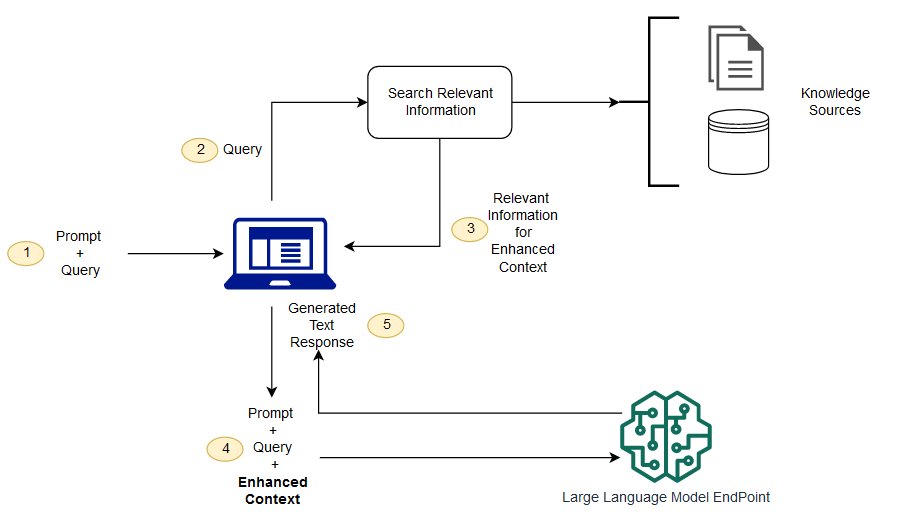
Wat is Retrieval Augmented Generation (RAG)?
Grote Taalmodellen (LLMs) worden getraind op enorme hoeveelheden tekstgegevens. Op basis van deze gegevens identificeert het model patronen en probeert het deze te repliceren tijdens de eigen tekstgeneratie. Bij het produceren van een output begint een LLM met een door de gebruiker geschreven prompt en wijst het algoritmisch waarschijnlijkheden toe aan “tokens” of woorden die waarschijnlijk het prompt opvolgen op basis van patronen die het heeft waargenomen in de oorspronkelijke trainingsgegevens. Daarom noemt OpenAI sommige van zijn API-eindpunten “Chat Completions” - het model probeert de invoer van de gebruiker aan te vullen.Voor een beter begrip van wat “tokens” zijn in de context van LLM’s, raadpleeg het volgende artikel uit de documentatie van OpenAI:
https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them