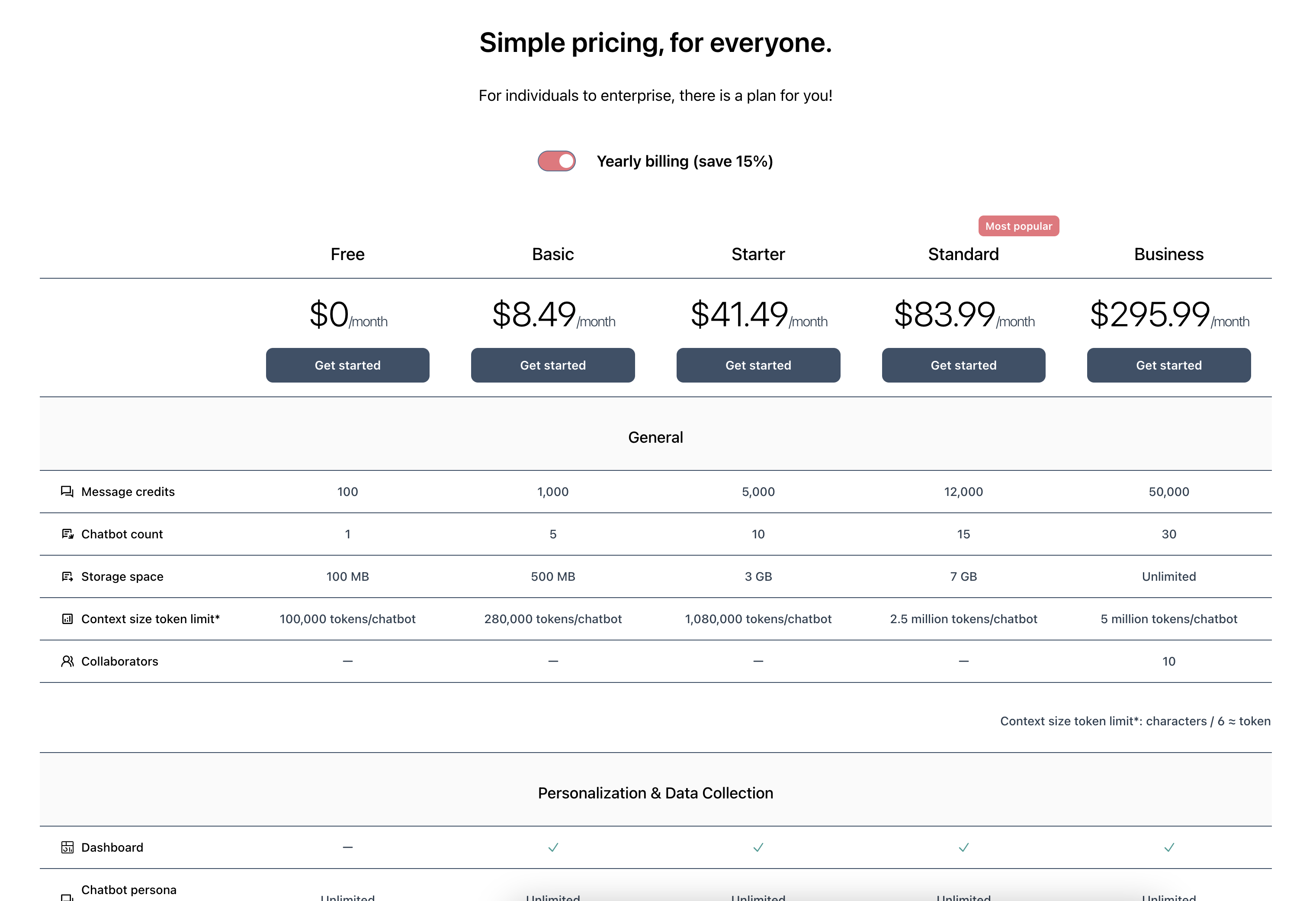
- Kwaliteit van je trainingsgegevens
- Keuze van het Large Language Model (LLM)
- Duidelijkheid van de basisprompt
Chunk-splitsing
Tijdens RAG worden chunks geselecteerd en samen met de basisprompt geïnjecteerd in de originele invoervraag van de gebruiker. Deze chunks worden direct afgeleid van je geüploade trainingsgegevens - PDF’s, Word-documenten, websites, TXT-bestanden, enz. Omdat LLM’s tokenlimieten hebben, moeten we ook beperkingen opleggen aan de grootte van deze chunks. Dit betekent dat zelfs als je oorspronkelijke document een lang hoofdstuk over één onderwerp bevat, het moet worden opgedeeld in meerdere chunks en afzonderlijk moet worden opgeslagen in onze vector-database. Hoe kunnen we een document opsplitsen met minimale wijzigingen in de oorspronkelijke betekenis? Helaas is er geen universele oplossing. Dit is nog steeds een lopend wetenschappelijk onderzoeksveld. Chatwize gebruikt een combinatie van regelgebaseerde en statistische relevantie-algoritmen om trainingsgegevens op te splitsen, maar we kunnen niet altijd garanderen dat elke chunk op zichzelf staand, schoon en nauwkeurig is. Gelukkig zijn LLM’s gespecialiseerd in het werken met ongestructureerde tekst en hebben ze een hoge tolerantie voor slecht geformatteerde invoer bij het genereren van antwoorden.Chunk-kwaliteit
Een andere bron van fouten komt voort uit de inhoud van de chunks zelf. Idealiter moet elke chunk op zichzelf staan, semantisch consistent en grammaticaal correct zijn. Als de documentstructuur belangrijk is, moet elke chunk ook relevante metadata bevatten die aangeeft waar in het document deze zich bevindt. Dit kan echter niet altijd worden gegarandeerd bij de extractie van chunks uit geüploade tekst. Deze fout is vooral merkbaar bij websites. Aangezien webbrowsers websites anders renderen dan hoe een webscraper ze ziet, kan wat jij ziet heel anders zijn dan wat onze scraper vastlegt. Bovendien gaan de meeste lay-outinformatie en gegevens die zich in afbeeldingen, illustraties en video’s bevinden, verloren tijdens het scrapingproces.